Esta semana no me apetecía ponerme a escribir cosas muy técnicas y buscando por algunas carpetas me encontré un documento con algunas de las preguntas más típicas que os pueden hacer en vuestra entrevista de trabajo para ser DBA de SQL Server.
Son preguntas y respuestas sobre todo de conceptos y enfocadas a un puesto de DBA junior, pero ey, menos es nada.
¿Cuáles son modelos de recuperación SQL Server (Recovery models) y para qué sirven?
Los modelos de recuperación o recovery models determinan las opciones de backup y restore disponible para cada base de datos y si se tomarán o no backups de los logs transaccionales y como se almacenarán.
Los logs transaccionales almacenan todas las modificaciones que se han hecho en al base de datos y ayudan mantener la integridad de la misma.
- Simple Recovery Model: Los logs transaccionales se borraran cada X tiempo. Este modo de recuperación no permite hacer una restauración a un punto concreto del tiempo, sólo al punto en el que se tomó el último backup full o diferencial. Los logs no crecerán de forma descontrolada y suelen mantener un tamaño pequeño.
- Full Recovery Model: Todas las modificaciones se quedarán grabadas en el archivo del log hasta que se haga un backup de ese archivo. Se pueden usar estos logs para hacer una restauración a cualquier punto del tiempo. Si el log tiene limite de tamaño y se alcanza, o el disco donde está almacenado se queda sin espacio, la base de datos no seguirá funcionando hasta que se haga un backup del log (esto elimina los datos dentro del archivo) o se expande el disco.
- Bulk Logger Recovery Model: Similar al anterior pero sin almacenar en los logs consultas muy pesadas como selects into, create indexs o bulk inserts.
¿Qué es la alta disponibilidad en SQL Server (SQL Server High Availability)? Definición y modelos.
La alta disponibilidad o high availability significa que los sistemas deben seguir funcionando con el menor downtime posible en caso de un fallo en uno de los nodos.
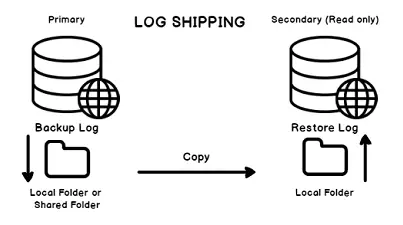
SQL Server Log Shipping
Requiere que la base de datos esté en full recovery model ya que depende en gran medida de los logs de transacciones.
Comienza restaurando la base de datos principal en los servidores secundarios, luego la base de datos secundaria se sincronizará mediante la copias de seguridad de los logs de transacciones de la base de datos principal. La base de datos secundaria no será accesible ya que permanecerá en modo de «sólo lectura».
Replicación en SQL Server
Consta de un servidor primario (Publisher) que distribuye todas las tablas de bases de datos (artículos) a los servidores secundarios (suscriptores) que también se pueden usar para generar informes. Trabaja con 3 agentes:
- SQL Snapshot Agent: Prepara el archivo de snapshot inicial. Como una copia de seguridad completa.
- Distribution Agent: Responsable de copiar la snapshot para los suscriptores.
- Log Reader Agent: Supervisa el registro de transacciones SQL en la base de datos del publisher y copia estas transacciones en la base de datos de distribución, para que se copien a los suscriptores.
SQL Server Mirroring
Las bases de datos deben estar configuradas en full recovery model. Se requiere al menos 2 servidores, uno primario, otro que será el mirror y opcionalmente podremos añadir un tercero llamado testigo (witness) que monitorizará la conexión entre estos dos servidores y realizará el failover automático o cambio de rol entre estos dos servidores cuando sea necesario.
Para configurar el mirroring tendremos que hacer un backup full y un backup de los logs y restaurarlos en el servidor secundario pero dejando la base de datos «restoring» para luego configurar el mirroring, aquí podéis ver un tutorial completo de como hacer esto.
Una vez que el mirroring esté configurado se usaran los logs de transacciones para sincronizarse en uno de estos 2 modos:
- Modo de alta seguridad (síncrono): la transacción se confirmará en la base de datos principal después de confirmarla y escribirla en el registro de transacciones en la base de datos espejo.
- Modo de alto rendimiento (asincrónico): la transacción se confirmará en el principal sin esperar a que se confirme en el servidor espejo. Más posibilidad de pérdida de datos pero menor latencia.
Always On Failover Cluster
Este sistema de alta disponibilidad se construye usando los servicios de clustering que ofrece Windows Server.
Consiste en un servidor principal (réplica principal) con una base de datos de lectura y escritura y una o más réplicas secundarias de solo lectura para fines de generación de informes. Si el servidor principal falla, la propiedad del grupo de recursos se moverá a otro nodo del clúster.
Para que sea más fácil para los usuarios, se suele crear un listener, que es un nombre virtual para el cluster, de esta forma los usuarios no tendrán que conectar directamente al nodo principal si no que lo harán al listener y este los dirigirá al actual nodo principal del Always On. Esto garantiza que un usuario no se conecte a un nodo secundario por error.
La réplica principal envía logs de transacciones a todas las réplicas y estas las escriben en sus bases de datos.
Performance Tuning en SQL Server (Optimización del rendimiento)
Esto es un apartado del SQL super grande y bastante complejo (es prácticamente magia negra), por lo que os daré algunos breves conceptos de los que podéis hablar si os preguntan. No os preocupéis, nadie espera que un DBA junior sepa mucho sobre esto (de hecho probablemente esperan que no sepas nada).
El performance tuning consiste en hacer que las consultas que se ejecutan en una base de datos se ejecuten lo más rápido y eficientemente posible, punto.
- Generar el plan de ejecución actual: Para diagnosticar consultas lentas se puede generar el plan de ejecución gráfico utilizando el SSMS. Esto se puede hacer en «consulta del motor de base de datos» y luego en «incluir plan de ejecución real».
- Supervisar el uso de recursos: Como utilizamos Windows, podemos usar el monitor de recursos para medir el rendimiento de la instancia SQL Server.
- Database Engine Tuning Advisor: Podemos usar esta herramienta para analizar la query que se está ejecutando y que pretendemos mejorar.
Índices en SQL Server
Los índices permiten que las consultas para la selección de datos se ejecuten más rápido y son una parte clave del alto rendimiento de SQL Server.
- Índice agrupado(Clustered Index): Ordena físicamente las páginas de datos por columnas que forman parte del índice agrupado. Se puede crear en una o varias columnas y solo puede tener un índice agrupado por tabla.
- Índice no agrupado(Non-Clustered Index): Están ordenados por el índice, pero eso no afecta los datos reales.
Espero que esta información os haya servido y recordad, si no sabéis la respuesta a alguna de las preguntas que os hacen, responder «no lo sé» siempre es la mejor opción.
2 comentarios en «Preguntas y respuestas para una entrevista de trabajo de DBA SQL Server»