Un cliente nos ha abierto un ticket para hacernos una pregunta sobre un disco que se había quedado sin espacio y que contenía los logs de las bases de datos, después de responderle con algunas recomendaciones y que nos confirmase que todo estaba bien nos añadió lo siguiente.
«Ya que estamos aquí, podría haceros otra pregunta…?» Jaja que casualidad que estamos aquí ya verdad? Pues supongo que si que puedes. Ahí vamos.
El cliente nos explica que tiene un clúster de alta disponibilidad en el que está instalando los jobs de mantenimiento de Ola Hallengren (si no sabéis lo que son, os dejo esta entrada en la que lo explico) y quiere saber si tiene que instalarlos en todos los nodos del clúster (spoiler, si).
Una vez le respondemos nos pregunta si hay alguna manera de instalar estos jobs pero que sólo se ejecuten en la instancia principal, esto evitará errores ya que las bases de datos en las replicas secundarias no son accesibles. Nuestra respuesta es que tiene que añadir un paso en todos los jobs para comprobar si la instancia es principal o no.
Os explico cómo, es bastante fácil.
Usar un script para comprobar si una instancia SQL Server es la principal en un AG
Comprobar manualmente si la instancia es la principal o no es bastante sencillo, simplemente abrimos el panel de control del grupo de alta disponibilidad y leemos con nuestros ojos cuál es la replica principal y cual es la secundaria.
Cuando la comprobación la tiene que hacer un job que se ejecuta automáticamente es más dificil (los jobs no tienen ojos) y tendremos que añadir un paso extra para comprobarlo.
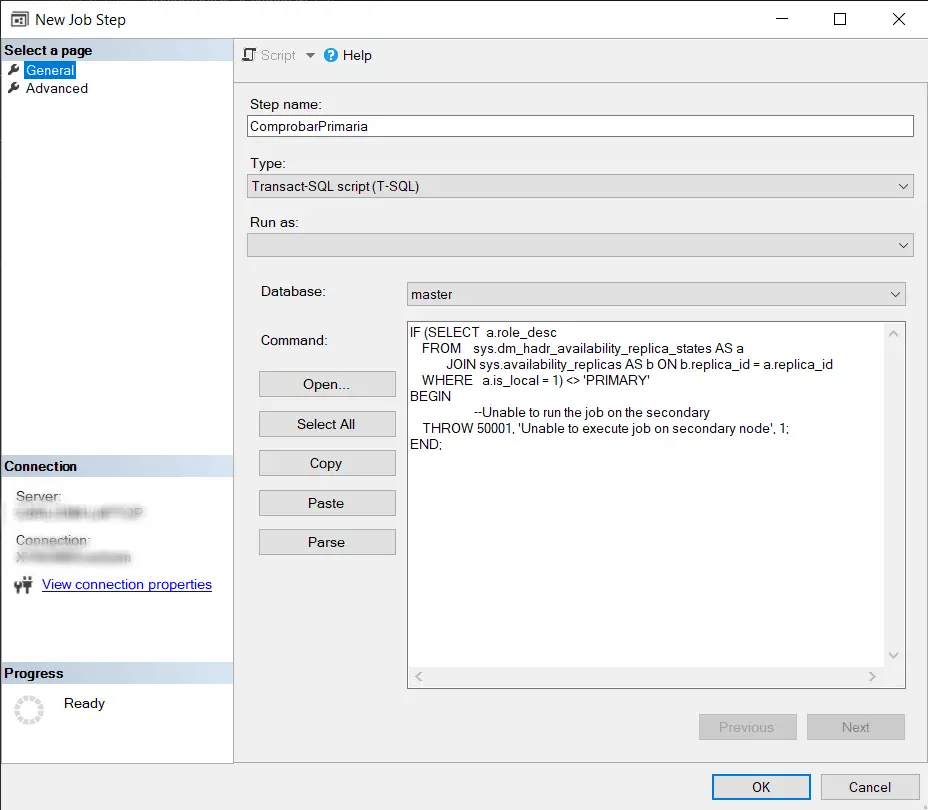
El script que usaremos es el siguiente:
IF (SELECT a.role_desc
FROM sys.dm_hadr_availability_replica_states AS a
JOIN sys.availability_replicas AS b ON b.replica_id = a.replica_id
WHERE a.is_local = 1) <> 'PRIMARY'
BEGIN
--Unable to run the job on the secondary
THROW 50001, 'Unable to execute job on secondary node', 1;
END;
Configurar los jobs para comprobar la replica primaria
Haremos click con el botón derecho encima del job y añadiremos un nuevo paso de la siguiente manera. Obviamente lo pondremos el primero ya que queremos que haga la comprobación y si la instancia no es la primaria no se ejecute nada más.

Dentro del job añadiremos el nombre del paso y lo que va a ejecutar (el script anterior).
En avanzado lo configuraremos de la siguiente manera:
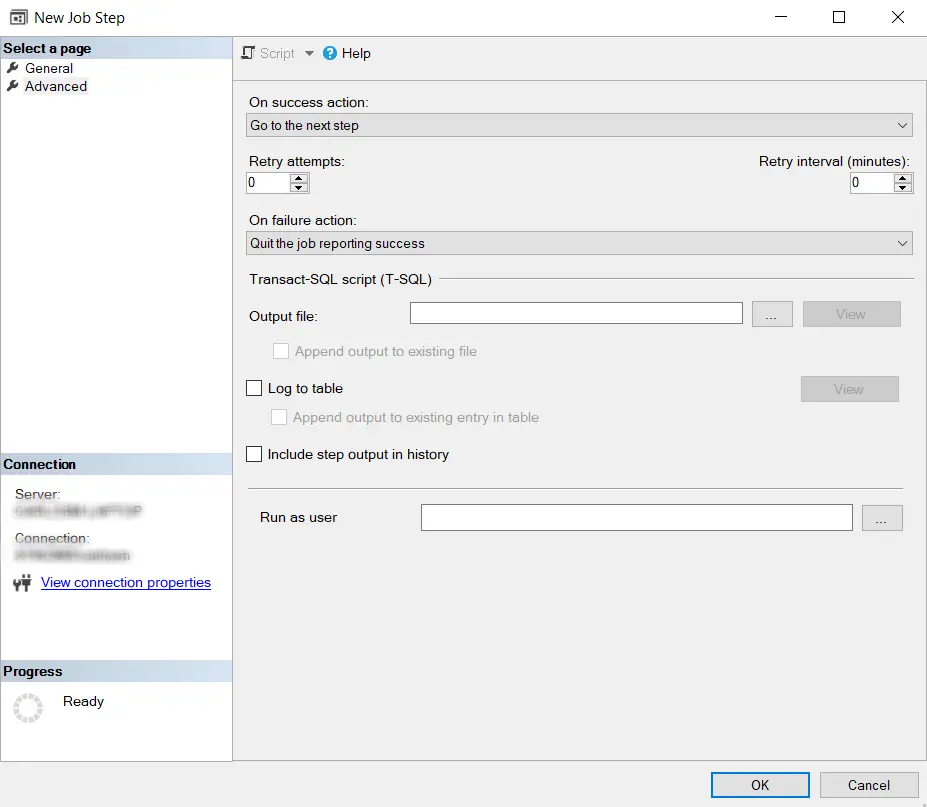
On success action: Go to next step. Si la instancia es primaria el script hará la ccomprobación y permitirá que se ejecute el job
On failure action: Quit the job reporting success. El step ejecutará el THROW que hará que se muestre como un paso fallido y por lo tanto la ejecución del job se detendrá.
Lo configuramos de esta forma para que no muestre que el job ha fallado ya que no queremos crear alerta falsas en los monitores, pero podéis configurarlo para que si se muestre.
Y esto es todo, así de rápido se puede añadir esta configuración que os salvará de bastante falsas alarmas.
Espero que esta información haya sido útil y no olvides que debes configurar este paso en todos los jobs.