
Estoy de guardia en mi trabajo y ayer de noche recibí una alerta informandome de que uno de los grupos de alta disponibilidad (Always On AG) estaba malito y por lo tanto los nodos no se estaban sincronizando.
Lo primero que hice es comprobar que ambos nodos estaban accesibles y funcionando (que no se hubieran caido) y que las instancias dentro de esos servidores también estaban funcionando. Todo correcto a primera vista, por lo que hice una investigación un poco más profunda en ambos nodos (visor de eventos, logs de SQL Server, Failover Cluster Manager Logs…) y aquí encontré el problema.
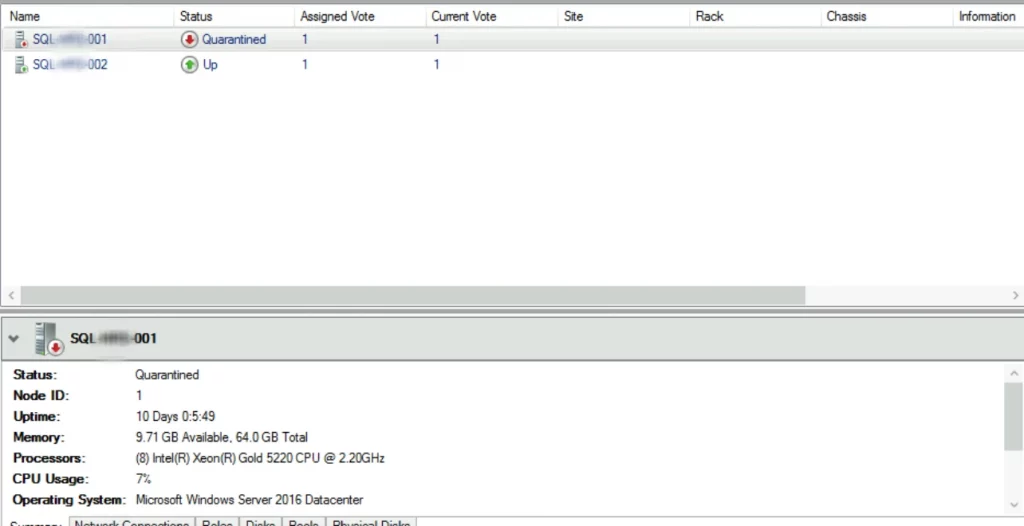
Nodo en cuarentena en un AG
Lo primero que me encontré nada más abrir el Cluster Manager es que uno de los roles estaba en estado «Quarantined». A simple vista esto puede dar a entender que el nodo está caido, pero os recuerdo que estaba literalmente conectado a ese nodo y conectado a la instancia, por lo que claramente estaba funcionando.
Qué quiere decir el estado «Quarantined» en un AG?
Basicamente el estado de «cuarentena» indica que, aunque el nodo pueda estar funcionando, ha sido excluido temporalmente del AG debido a que tuvo un problema y falló al unirse de nuevo al AG en varias ocasiones durante un periodo corto de tiempo (lo normal son 3 intentos en la última hora).
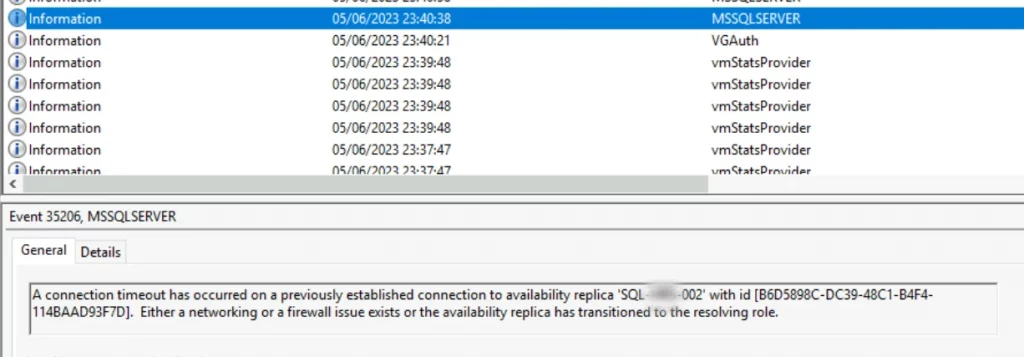
En este caso esto fue provocado por un error en la red del cliente que provocó que los nodos no pudiesen comunicarse entre ellos y por lo tanto se rompiese la sincronización.
Pues vale, son las 2:30 de la mañana y tengo este problema, gracias por la información, pero que hago ahora.
Sacar un nodo de la cuarentena y unirlo de nuevo al AG
Aquí tenemos 2 opciones:
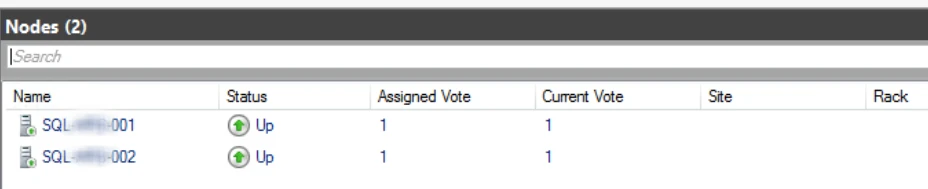
- No hacer nada y esperar: Parece de coña, pero no. Una caracterista de este estado de cuarentena es que es temporal y después de 2 horas se intentará unir el nodo afectado de forma automática al AG de nuevo, por lo que podriamos sólo asegurarnos de que todos los problemas fueran resuelto y esperar a que esto ocurra. Siendo honesto esto es lo que yo hice ya que sólo tenia que esperar 10 minutos.
- Cambiar el estado del nodo manualmente: Si teneis que esperar mucho tiempo y necesitais que esto se solucione urgentemente, podeis sacar el nodo del estado de cuarentena y unirlo al AG usando el siguiente comando en PowerShell.
Start-ClusterNode -ClearQuarantine
Y poco más, la verdad es que ha sido un caso extraño que nunca habia visto y que me encontré de repente y que tuve que solucionar sobre la marcha. Si ahora mismo estais en esta situación, espero que os haya solucinado el problema y os podais ir a dormir.
Mil gracias, me valió en una situación similar.
Tengo una pregunta, ¿te volvió a pasar?. Tengo un entorno híbrido, mitad on-premise y mitad en AWS, y el nodo que tengo en AWS me está volviendo loca, alguien tocó la configuración de la tarjeta de red, y no sé si algo más, y desde entonces parece que no se llevan muy bien los dos nodos y el de AWS entra en cuarentena cuando la parece.
Mil gracias por tu tiempo.
Buenas Yoli
Primero de todo muchas gracias por el comentario.
No me ha vuelto a pasar y no es un problema que haya visto o vea frecuentemente.
Sin tener muchos más datos sobre tu entorno, diría que esto parece más un problema para el departamento de redes/Windows que para un DBA (pero tampoco sé si tu empresa dispone de esto o si estás sola ante el peligro).
Pocas recomendaciones puedo hacerte aquí que, supongo, no hayas hecho ya. Busca en los logs de ambas instancias y en el log del cluster manager. Busca si este problema se repite con un patrón (a las mismas horas o días, después de ciertas tareas, etc.)
¡Mucha suerte!